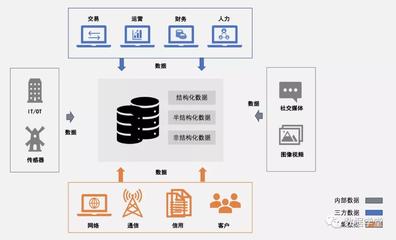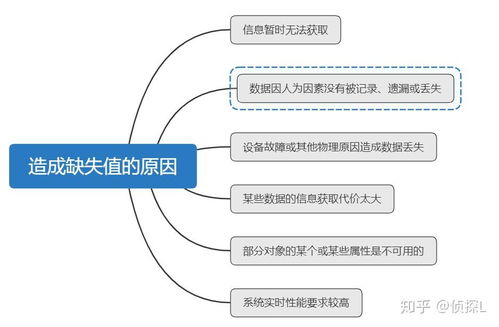
随着人工智能技术的飞速发展,大型语言模型(LLM)已成为推动行业创新的核心引擎。支撑这些庞然大物高效运行的背后,是日益复杂和挑战性的数据存储与管理需求。本文将深入探讨在大模型实践中,如何协同优化存储性能、控制成本,并驾驭多云环境下的数据处理与存储策略。
一、性能:为模型训练与推理提供高速通道
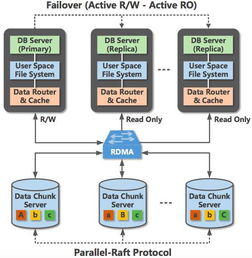
大模型的训练涉及海量参数的反复读写与更新,对存储系统的吞吐量、IOPS(每秒输入/输出操作次数)和延迟提出了极致要求。高性能存储解决方案,如全闪存阵列、分布式存储系统以及高性能并行文件系统(如Lustre, GPFS),已成为支撑千亿乃至万亿参数模型训练的基石。它们能够确保数据管道永不成为瓶颈,让宝贵的计算资源(如GPU集群)时刻处于饱和工作状态。在推理阶段,低延迟存储则直接关系到终端用户的体验,需要针对模型加载、缓存和实时数据访问进行专门优化。
二、成本:在资源需求与预算间寻找最优解
追求极致性能的成本控制是无法回避的现实。大模型存储的成本构成复杂,包括硬件采购、软件许可、机房空间、电力消耗、运维人力及云服务费用等。实践中常采用分层存储策略:将热数据(如正在训练的数据集、检查点)存放于高性能层,而将温冷数据(如历史训练日志、归档模型)迁移至成本更低的对象存储或磁带库。数据去重、压缩技术能有效降低存储空间占用。利用云原生的弹性与按需付费特性,在训练高峰期快速扩展高性能存储,在空闲期缩减资源,是实现成本效益最大化的重要途径。
三、多云数据处理与存储:构建灵活稳健的架构
单一云或数据中心已难以满足全球化、高可用的需求,多云策略成为主流。这为数据存储带来了新的维度:
- 数据编排与同步: 需要工具与策略来管理跨云的数据流动,确保训练数据的一致性,并高效地将模型部署到不同区域的推理端点。
- 存储抽象与可移植性: 通过Kubernetes CSI(容器存储接口)或存储抽象层,实现应用与底层云存储服务的解耦,避免供应商锁定,提升架构灵活性。
- 合规与数据治理: 不同地区的数据驻留(Data Residency)法规要求数据存储在特定地域。多云存储架构需内置策略引擎,自动满足合规要求。
- 灾备与业务连续性: 将关键模型和数据跨云备份与复制,是防范区域性服务中断、保障业务连续性的关键。
实践建议与未来展望
成功的存储实践始于对业务场景的深刻理解。团队应首先明确工作负载特性(是训练密集型还是推理密集型),制定清晰的SLA(服务等级协议)。建议采用“数据湖仓一体”架构,统一管理原始数据、特征库和模型资产,并配备强大的元数据管理系统。
存储系统将更加智能化,能够主动预测数据访问模式并进行预置或迁移。存储与计算的协同设计也将更加紧密,如计算存储分离架构的进一步演进,以及存算一体等新型硬件技术的探索,有望从根本上重塑大模型的基础设施范式。
大模型存储绝非简单的硬件堆砌,而是一个需要持续权衡性能、成本与多云复杂性的系统工程。构建一个高效、经济、灵活且稳健的存储底座,是释放大模型全部潜力的必要前提。