在大数据解决方案的构建中,数据处理与存储环节是核心支柱,它决定了数据的流动方式、处理效率以及最终的价值呈现。为了系统化地设计和构建这些复杂环节,架构师们常常依赖一系列经过验证的模式。本文将深入探讨用于数据处理与存储的原子模式和复合模式,揭示它们如何协同工作以构建健壮、可扩展的大数据系统。
一、原子模式:构建解决方案的基本单元
原子模式是不可再分的基础构建块,每个模式都针对数据处理流水线中的一个特定、单一的挑战。
- 数据捕获模式:此模式专注于如何高效、可靠地将数据从源头引入系统。关键实现包括:
- 事件流摄取:适用于高吞吐、低延迟的实时数据,如使用Apache Kafka作为消息队列,持续捕获用户点击流或IoT传感器数据。
- 批量摄取:用于周期性的大规模数据迁移,例如在每日凌晨将前一天的交易日志从关系数据库导入Hadoop分布式文件系统(HDFS)。
- 变更数据捕获(CDC):实时捕捉源数据库的增量变更,确保数据仓库或数据湖与源系统同步。
- 数据存储模式:定义了数据在系统中的持久化方式,根据访问需求选择不同结构。
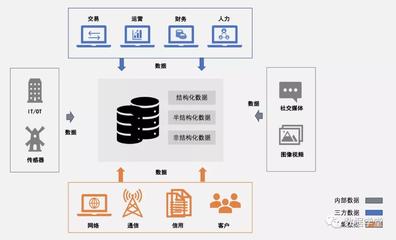
- 原始数据存储:通常采用分布式文件系统(如HDFS)或对象存储(如Amazon S3),以原始格式(如JSON、CSV)保存数据,保留最大灵活性,支撑数据湖架构。
- 处理就绪存储:将原始数据清洗、转换后,以更高效的列式格式(如Parquet、ORC)存储,为后续分析查询优化性能。
- 聚合数据存储:存储预计算的结果或高度聚合的数据,通常服务于特定应用或高频查询,如存储在Redis中的实时仪表盘数据。
- 数据处理模式:描述了数据转换和分析的核心逻辑单元。
- 批处理模式:对静态数据集进行有界计算,典型代表是MapReduce作业,适用于ETL、历史报表生成等对延迟不敏感的任务。
- 流处理模式:对无界数据流进行连续、低延迟的计算,如使用Apache Flink或Apache Storm进行实时欺诈检测或监控告警。
- 交互式查询模式:提供亚秒级到秒级的查询响应,通过如Apache Impala、Presto等引擎直接查询存储在HDFS或对象存储上的大规模数据集。
二、复合模式:原子模式的战略组合
复合模式通过将多个原子模式以特定方式组合,来解决更复杂的业务场景。它们是面向解决方案的蓝图。
- Lambda架构:这是一个经典的复合模式,旨在平衡批处理与流处理的优势。它包含三个层次:
- 批处理层:使用批处理模式处理全量数据,生成精准但高延迟的“批处理视图”。
- 速度层(流处理层):使用流处理模式处理最新数据,生成近实时但可能近似的“实时视图”。
* 服务层:合并批处理视图和实时视图,为应用提供统一的数据查询接口。
该模式确保了系统的容错性和数据准确性,但维护两套逻辑的复杂性是其挑战。
- Kappa架构:作为对Lambda架构的简化,它主张所有数据处理都通过流处理模式完成。历史数据通过重新播放事件流来支持。这简化了架构,但对流处理引擎的可靠性和状态管理能力提出了极高要求。
- 数据湖模式:这是一个以存储为中心的复合模式。它组合了原始数据存储(接收所有原始数据)、批处理与流处理(用于数据清洗、转换与丰富),以及交互式查询(供数据科学家和分析师探索数据)。其核心是建立一个集中的、容纳各种原始格式数据的存储库,从而实现数据的民主化访问和避免早期建模导致的信息孤岛。
三、模式选择与实践考量
选择和应用这些模式时,需综合考虑以下因素:
- 数据特性:数据量(Volume)、速度(Velocity)、多样性(Variety)决定了存储和处理的基线要求。
- 业务需求:对数据准确性的要求(精确一致 vs. 最终一致)、查询延迟(实时 vs. 准实时 vs. 离线)是选择批处理、流处理或混合架构的关键。
- 系统目标:是优先考虑开发运维的复杂性(倾向于Kappa),还是优先保证结果的绝对准确性(倾向于Lambda)。
- 技术生态:现有团队技能栈与所选模式技术栈(如Hadoop生态、Spark生态、Flink生态)的匹配度。
###
数据处理与存储的原子模式与复合模式,为大数据架构师提供了从微观到宏观的设计语言。理解每个原子模式的职责与局限,是灵活运用它们的基础;而掌握复合模式的组合哲学,则是设计出能够优雅应对复杂业务挑战的整体解决方案的关键。在实践中,往往需要根据具体场景对这些模式进行裁剪和定制,从而构建出既高效又可持续演进的大数据系统。